Reinforcement learning algorithms require an exorbitant number of interactions to learn from sparse rewards.
To overcome this sample inefficiency, we present a simple but effective method for learning from a curriculum of increasing number of objects. We show that attention-based graph neural networks provide critical inductive biases that enable usage of this task curriculum. Our agent achieves a success rate of 75% for
stacking 6 blocks, while the existing state-of-the-art method, which uses human demonstrations and resets,
only achieves a success rate of 32%. Our method is also orders of magnitude more sample efficient.
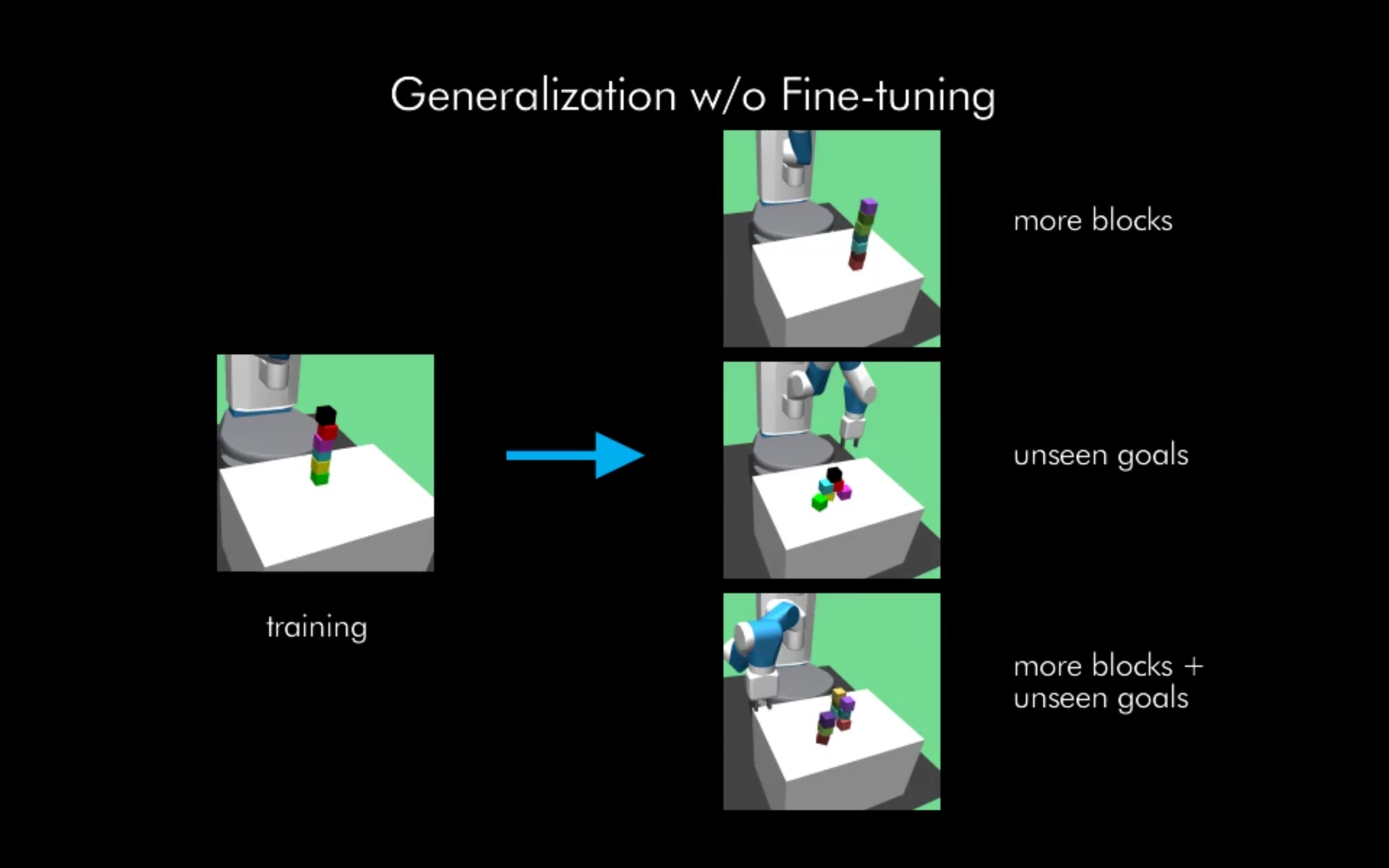
Zero-shot Generalization
We show zero-shot generalization to different block configurations and block cardinalities. Our system can stack blocks
into taller towers, multiple towers and pyramids without additional training. While these results are exciting,
we acknowledge there is substantial room for improving the zero-shot results.
Emergent Behaviors
1.
2.
3.
Singulation: (0:02) In order to not knock over the tower, the agent singulates the final black block before picking and placing it.
Pushing while grasping: (0:03) The agent performs a rolling/pushing behavior on the green block while grasping the blue block.
Pick 2, place 2: (0:03) The agent collects the blue and yellow blocks in hand before placing each one by one.
Failure Modes
1.
2.
3.
4.
Oscillation: The agent oscillates its end-effector without progressing towards the goal.
Often, this happens when the target block is very close to the base of the tower. In this scenario,
picking up the block risks toppling the tower. We hypothesize that in order to reduce this risk, the agent
simply oscillates its end-effector.
Insufficient recovery time: After 6 blocks have been stacked into a tower, the tower topples.
The agent restarts stacking but is unable to stack all the blocks within the maximum time length of the episode.
Blocks fall off during stacking: While stacking a tower of 6 blocks, the agent knocks one or more blocks off the table.
Because the blocks are no longer on the table, the agent does not succeed.
Blocks fall off after stacking:
The agent succeeds in stacking a tower of 6 blocks, but the tower topples and block(s) fall off the table.
Source Code and Environment
We have released the PyTorch based implementation and environment on the Github page. Try our code!
Citation Richard Li, Allan Jabri, Trevor Darrell, Pulkit Agrawal. Towards Practical Multi-object Manipulation using Relational Reinforcement Learning. In ICRA 2020.
@inproceedings{li19relationalrl,
Author = {Li, Richard and
Jabri, Allan and Darrell, Trevor and Agrawal, Pulkit},
Title = {Towards Practical Multi-object Manipulation using Relational Reinforcement Learning},
Booktitle = {arXiv preprint arXiv:XXXX},
Year = {2019}
}
Acknowledgements
We acknowledge support from US Department of Defense, DARPA's Machine Common Sense Grant and the BAIR and BDD industrial consortia.
We thank Amazon Web Services (AWS) for their generous support in the form of cloud credits.
We'd like to thank Vitchyr Pong, Kristian Hartikainen, Ashvin Nair and other members of the BAIR lab and the Improbable AI lab
for helpful discussions during this project. Template credit.
 [Paper]
[ArXiv]
[Paper]
[ArXiv]